crawler-08 中国大学排名定向爬虫
有人的地方就有江湖,有大学的地方就有排名,这里以最好大学网为例,爬取其中的大学排名情况。
1、项目简介
1)网址:http://www.zuihaodaxue.com/Greater_China_Ranking2019_0.html2
2)robots协议:http://www.zuihaodaxue.com/robots.txt
如下图,该网站根目录下没有robots.txt,默认任意爬虫可以无限制地对该网站进行爬取。
2、功能描述
1)输入:大学排名URL链接;
2)输出:大学排名信息的屏幕输出(排名,大学名称,总分);
3)技术路线:requests‐bs4;
4)定向爬虫:仅对输入URL进行爬取,不扩展爬取其他url;
3、项目准备
1)可行性分析(法律角度)
该网站根目录下没有robots.txt,默认任意爬虫可以无限制地对该网站进行爬取。
2)可行性分析(技术角度)
需要分析一下,我们要爬取的信息是否都写在了HTML页面之中,因为有一部分数据,可能是通过javascript等脚本语言生成的,即动态网页。动态网页有一部分数据是动态生成和提取的,在这种情况下,用requests‐bs4两个库,是无法获取其动态信息的。
如下图,通过浏览器查看网页源代码,可以看到如下图,所需数据均可以查看到。
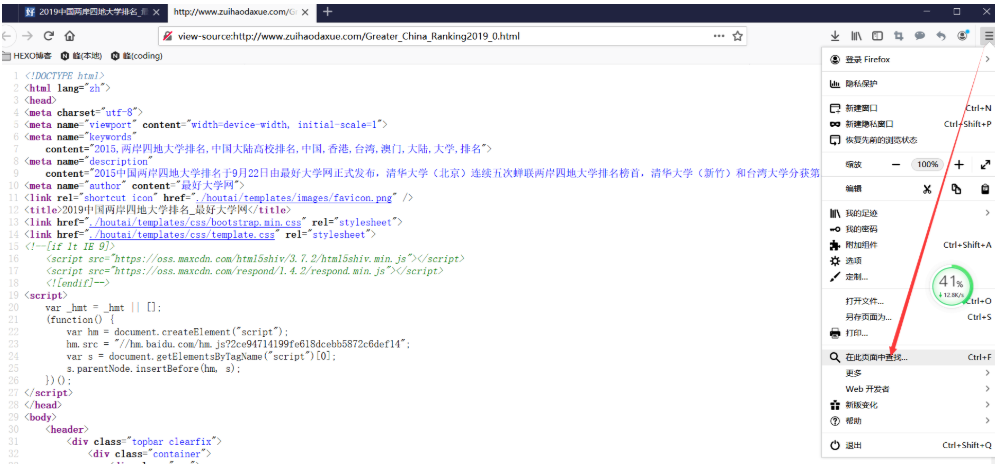
如下图,在这个页面查找“香港大学”,将这一行html代码复制下来进行查看。
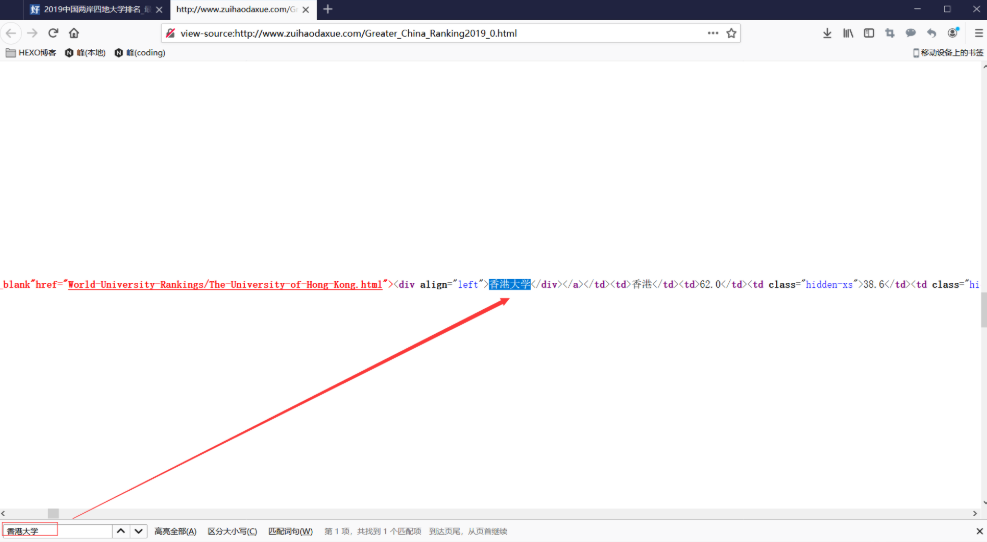
复制下来的代码如下,每一个 tr 标签索引着一段信息,每一段信息对应一所大学;在每段信息中,每一个 td 标签里,分别存放着我们需要提取的“ 排名,大学名称,总分 ” 这些信息。
1 | <tbody> |
4、程序的结构设计
1)从网络上获取大学排名网页内容;自定义getHTMLText()方法。
获取内容,用get() 方法即可,加上一个通用代码框架,如下。
1 | def getHTMLText(url): |
2)提取网页内容中信息到合适的数据结构;自定义fillUnivList()方法。
将getHTMLText() 方法得到的html页面,提取相关信息存放入一个ulist列表之中;注意这个函数除了from bs4 import BeautifulSoup类以外,还需要import bs4库,因为要使用其对应的标签类型定义。
isinstance函数检测 tr 标签的类型,如果不是bs4.element.Tag类型,则过滤掉;
ulist.append()函数增加了ulist列表的字段:“ 排名,大学名称,总分 ” 。
注意:ulist是一个二维列表;例如ulist[0]表示清华大学那一行,而ulist[0][0]表示的是那一行的第一列,即清华大学的排名“1”。
1 | def fillUnivList(ulist, html): |
3)利用数据结构展示并输出结果;自定义printUnivList()方法。
将ulist列表之中之中的信息打印出来,num参数指定打印的元素数量;用format() 函数完成格式化输出,打印表头和表内容。
1 | def printUnivList(ulist, num): |
4)总结:
为什么称函数为接口?例如getHTMLText(url) 函数,一头接入url,另一头接出爬取下来的网页内容,看起来就像一个方便好用的转换接头一样;
因此,将函数称为接口,是最形象的比喻;
正如上面的三个函数,一环套一环,一个接口接着另外一个接口,各司其职完成整个程序的功能运行,是最基础的编程思想。
5、程序源代码
1)原始代码
此代码已经实现了预期功能,但是大学名称各有长短,导致看起来并不整齐美观,源码如下。
1 | # CrawUnivRankingA.py |
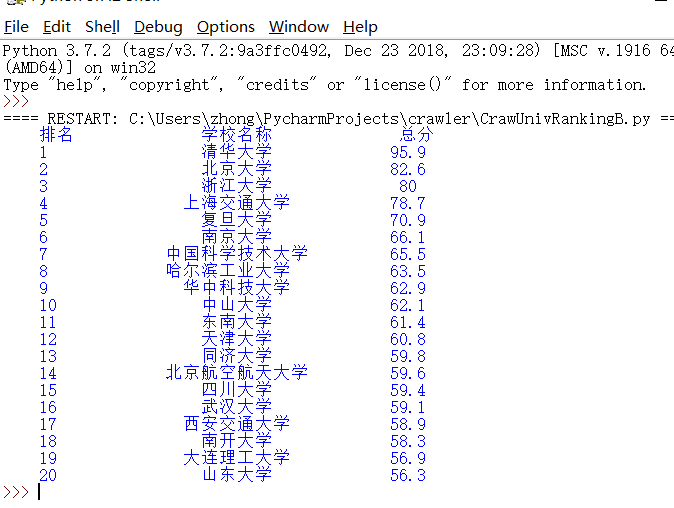
运行结果:

2)优化后的代码
问题分析:当中文字符宽度不够时,默认采用西文字符填充;然而中西文字符占用宽度不同,导致第二列不能对齐。下面的代码利用format函数采用中文字符的空格进行填充,解决了第二列的对齐问题。
format() 函数参数定义:
由其填充、宽度定义可知对齐问题的原因。

1 | #采用中文字符的空格填充,参数如下 |
注意事项:类似上例,对中英文混排输出问题进行优化,是爬虫之中经常要用到的手段,需要熟练掌握
源码:
1 | # CrawUnivRankingB.py |
运行结果: