mysql-06 SQL
基础概念
SQL(Structured Query Languege)结构化查询语言,是关系数据库的标准语言,功能强大,是一种通用的关系数据库语言。
关于大小写
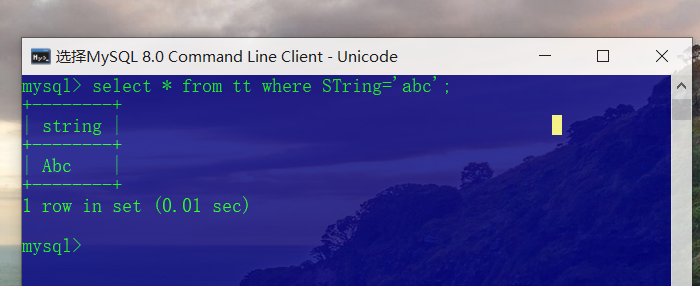
SQL Server和mysql对英文字母大小写不敏感,如下图,无论是关键字select、where等,还是被查找的内容字符串,亦或者是表名,一律对大小写不敏感。
SQL语句执行顺序
1)from
2)join
3)on
4)where
5)group by(按照后续条件分组)
6)聚集函数(avg,sum等)
7)having(按照后续条件筛选分组)
8)计算所有表达式
9)select
10)distinct(删除重复行)
11)order by(对结果排序)
举例
1 | select sname from student where student.sno='31606'; |
SQL数据定义语句
| 对象\操作 | 增 | 删 | 改 |
|---|---|---|---|
| 模式 | create schema | drop schema | 先删,再增加 |
| 表 | create table | drop table | alter table |
| 视图 | create view | drop view | 先删,再增加 |
| 索引 | create index | drop index | alter index |
举例
1、定义模式
定义模式实际上定义了一个命名空间,在这个空间中可以进一步创建基本表、视图和定义授权。
1 | #为用户zhang 创建一个模式test,并且在其中定义一个表tab1 |
2、删除模式
1)cascade(级联):删除模式的同时,删除其中所有数据库对象(表、视图等);
2)restrict(限制):删除模式时,若其中有数据库对象(表、视图等),则拒绝执行此删除操作,直接报错;而当其中没有任何下属对象时才可以成功执行drop schema语句。
1 | 1)drop schema zhang cascade; |
3、定义基本表(基表)
1)建表的同时,通常会加入完整性约束条件,通常有以下几种
primary key(主码)
unique(唯一值)
not null(不能取空值)
foreign key(外码)
PS:参照表和被参照表可以是一个表
2)建表时还要考虑数据类型,以下是常用的几种(不同关系数据库管理系统支持的数据类型不完全相同)
| 数据类型 | 含义 |
|---|---|
| char(n) | 定长字符串,长度为n |
| varchar(n) | 变长字符串,最大长度为n |
| int | 长整数,4B(字节) |
| smallint | 短整数,2B |
| bigint | 大整数,8B |
| float | 可选精度的浮点数,精度至少n位数字 |
| boolean | 逻辑布尔量 |
| date | 日期,格式YYYY-MM-DD |
| time | 时间,格式HH:MM:SS |
3)定长变长的区别
char(n)是定长格式,格式为char(n)的字段固定占用n个字符宽度,如果实际存放的数据长度超过n将被截取多出部分,如果长度小于n就用空字符填充。
varchar(n)是变长格式,这种格式的字段根据实际数据长度分配空间,不浪费对应的空间,但是搜索数据的速度会慢一点。
实例:学生数据库
1 | #学生表 |
4、修改基本表
1)注意drop某一列的时候也有cascade(级联)和restrict(限制)的区别
- cascade(级联):删除列的同时,级联删除引用了该列的其他对象(例如视图);
- restrict(限制):删除列时,如果该列被其他对象引用,则RDBMS拒绝此删除操作,直接报错;如果此时该列未被任何其他对象引用,则可以成功drop。
格式
1 | alter table 表名 |
举例
1 | #向student表增加一列“资产”,要求不能取空值 |
5、删除基本表
1 | drop table 表名 restrict|cascade |
1)cascade(级联):删除表的同时,相关的依赖对象(例如视图)也会被一起删除;不仅数据和表的定义被删除,而且此表上建立的索引、触发器等对象也都将被删除;如果该表被其他表引用,则会牵连其他表一起被删除。(例如SC表外码sno引用student,删除student后,SC也会被级联删除)。
2)restrict(限制):删除表时,若该表被其他表约束所引用,例如(check、foreign key等),删除会失败;若该表有视图、触发器、存储过程或者函数等依赖该表的对象,则删除会失败。
6、建立索引
当表的数据量比较大时,查询操作会比较耗时,建立索引可以加快查询速度。
1 | create [unique][cluster] index 索引名 on 表名(列名 次序,列名,次序,~) |
参数解析
1)unique:此索引每一个索引值只对应唯一的数据记录
2)cluster:此索引为聚簇索引
3)次序:默认为ASC(升序),另一个DESC(降序)
举例
1 | #SC表按学号升序、课程号降序建立唯一索引 |
注意
索引可以减少查询操作的时间,但是若数据增删改频繁,则系统要话费许多时间来维护索引吗,得不偿失反而降低查询效率,这时就需要删除一些不必要的索引了。

