crawler-06 Beautiful Soup
一、概念引入
Beautiful Soup,也称美丽汤,可以对html、xml格式进行解析并且提取其中相关信息;Beautiful Soup可以对你所要求的各种格式进行爬取,并且进行树形解析。
原理:将目标文档当做一锅汤,然后煲制这锅汤。
二、实际使用
1、安装
如果有pacharm的话,直接在settings里面的project interpreter点点点安装bs4即可;也可以通过cmd来安装,命令如下:
1 | pip install beautifulsoup4 |
2、测试
1)打开下面的链接,右键查看源代码
1 | https://python123.io/ws/demo.html |
2)可以看到源代码的格式
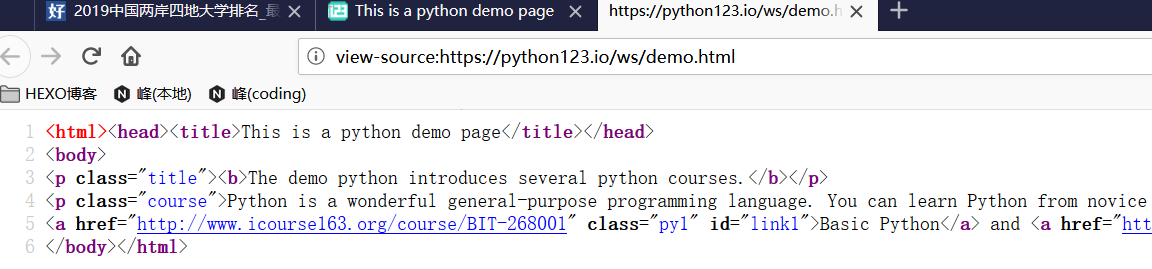
3)用requests爬取这个页面源代码
可以看到打印出来的内容,连个换行都没有,所有内容挤在一起;
1 | >>> import requests |
4)用bs4库处理文本
- 尽管安装的是beautifulsoup4,但使用的时候用的是简写:bs4;
- 注意python对大小写很敏感,BeautifulSoup中B和S要大写;
- html.parser是一种对html格式的解释器;
- soup=BeautifulSoup(demo,”html.parser”)就熬制了一锅汤,定义了一个soup;
1 | >>> demo=r.text |
可以看到打印出来的文本变得有序很多,不再是一整段;
5)BeautifulSoup的使用
1 | from bs4 import BeautifulSoup |
三、BeautifulSoup库的基本元素
Beautiful Soup库是解析、遍历、维护“标签树”的功能库;如下图,各种标签互有上下游的关系,从而组长了标签树;只要你提供的文件是标签树类型的,那么就可以用BeautifulSoup库完成解析。
1 | <html> |
1)Beautiful Soup库标签的理解如下图:

2)BeautifulSoup类的基本元素:

1、引用
Beautiful Soup库,也叫beautifulsoup4 或bs4 约定引用方式如下,即主要是用BeautifulSoup:
1 | from bs4 import BeautifulSoup |
2、理解
html文档、标签树、BeautifulSoup类三者等价;BeautifulSoup对应一个HTML/XML文档的全部内容;如下例子中,对象soup是熬制过的html文档。
1 | soup = BeautifulSoup('<p>data</p>','html.parser') |
3、Beautiful Soup库的解析器
| 解析器 | 使用方法 | 条件 |
|---|---|---|
| bs4的HTML解析器 | BeautifulSoup(mk,’html.parser’) | 安装bs4库 |
| lxml的HTML解析器 | BeautifulSoup(mk,’lxml’) | pip install lxml |
| lxml的XML解析器 | BeautifulSoup(mk,’xml’) | pip install lxml |
| html5lib的解析器 | BeautifulSoup(mk,’html5lib’) | pip install html5lib |
4、打印BeautifulSoup类的基本元素
1)name和attributes元素
1 | >>> from bs4 import BeautifulSoup |
2)NavigableString元素(继续使用上面的IDLE,省得重新熬汤)
就是打印标签内的字符串,如下:
1 | >>> soup.a |
3)Comment元素
打印注释内容,不会把<!–这种尖括号的印出来;
1 | >>> newsoup=BeautifulSoup("<b><!--This is a comment--></b>") |
四、基于bs4库的HTML内容遍历方法
1、html基本格式
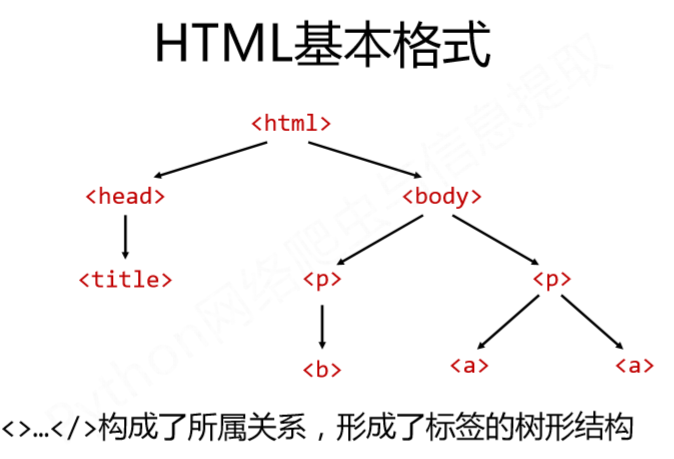
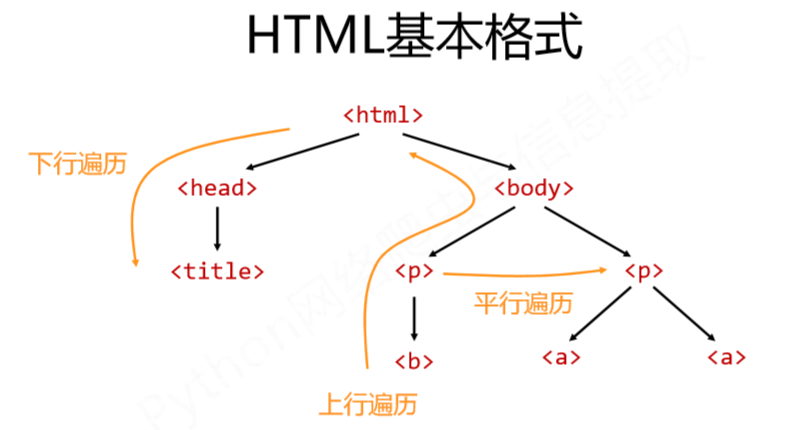
2、遍历方式
3、标签树的下行遍历
| 属性 | 说明 |
|---|---|
| .contents | 子节点的列表,将 tag 所有儿子节点存入列表 |
| .children | 子节点的迭代类型,与.contents类似,用于循环遍历儿子节点 |
| .descendants | 子孙节点的迭代类型,包含所有子孙节点,用于循环遍历 |
1 | #准备工作 |
使用for循环进行遍历
1 | #遍历儿子节点 |
4、标签树的上行遍历
| 属性 | 说明 |
|---|---|
| .parent | 节点的父亲标签 |
| .parents | 节点先辈标签的迭代类型,用于循环遍历先辈节点 |
1 | #title标签的父亲是head标签 |
5、标签树的平行遍历
| 属性 | 说明 |
|---|---|
| .next_sibling | 返回按照HTML文本顺序的下一个平行节点标签 |
| .previous_sibling | 返回按照HTML文本顺序的上一个平行节点标签 |
| .next_siblings | 迭代类型,返回按照HTML文本顺序的后续所有平行节点标签 |
| .previous_siblings | 迭代类型,返回按照HTML文本顺序的前续所有平行节点标签 |
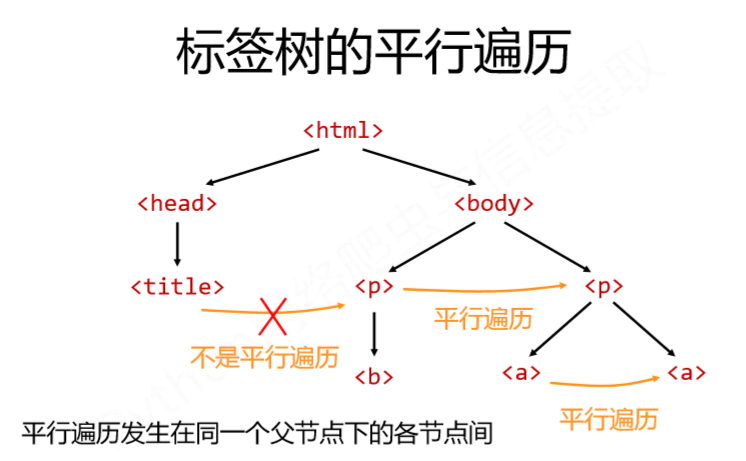
1 | #平行遍历获得的下一个节点不一定是标签类型 |
利用for循环完成平行遍历
1 | #遍历后续节点 |
五、基于bs4库的HTML格式输出
如何让html页面更加“友好”地显示?“友好”既针对人,也针对程序。
1、bs4库的prettify()方法
跟右键查看网页源代码一样的格式,打印html代码;
1 | >>> soup.prettify |
2、bs4库的编码和python3的默认编码一样,都是‘utf-8’,因此可以很方便地显示中文;如果用的是python2,那么就很鸡肋,需要无止尽地做编码转换,以下是python3:
1 | >>> soup1=BeautifulSoup("<p>中文</p>","html.parser") |

