crawler-05 网络爬虫实例
实例1:京东商品页面的爬取
京东商品页面简单地使用get() 方法即可爬取;
1 | import requests |
实例2:亚马逊商品页面的爬取
1、爬取报错503,爬取出错
1 | >>> import requests |
可以看到r.text返回一些报错信息,这说明爬取出错并非网络问题,而是服务器做了网络爬虫限制;对网络爬虫限制,常见的如下:
1)来源审查:判断User‐Agent进行限制(技术层面限制)
检查来访HTTP协议头的User‐Agent域,只响应浏览器或友好爬虫的访问;
2)发布公告:Robots协议(道德层面限制)
告知所有爬虫网站的爬取策略,要求爬虫遵守;
这里判断,可能是网站对User‐Agent进行了限制,下面进行验证。
2、查找出错原因
网站一般只接受有浏览器发起的请求,而对于爬虫的请求可以拒绝;如下,通过查看请求r的头部信息的User-Agent字段,可以看到我们很实在地告知亚马逊我们是一个pyhon爬虫程序而不是浏览器,因此被拒绝导致出错。
1 | >>> r.request.headers |
3、解决错误
Mozilla/5.0是一个标准的浏览器身份标识字段,可能被识别为火狐、谷歌、IE10等;
1 | >>> kv={'User-Agent': 'Mozilla/5.0'} |
4、完整代码
1 | import requests |
实例3:百度/360搜索关键字提交
1、了解搜索引擎接口网址
1)百度的关键词接口: http://www.baidu.com/s?wd=keyword
2)360的关键词接口: http://www.so.com/s?q=keyword
3)如何得知接口网址:
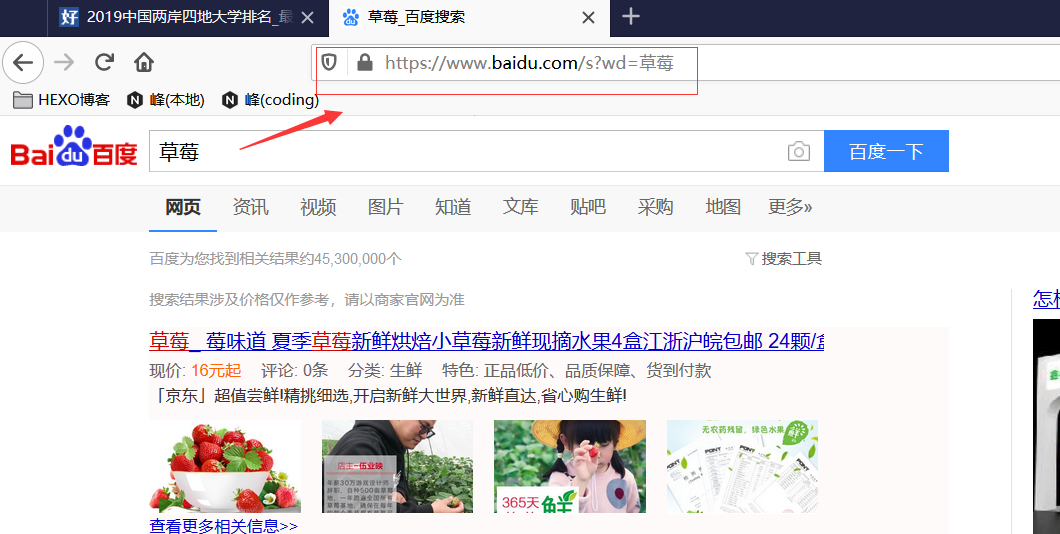
如下图,直接百度上搜”草莓“,结果可以看到网址栏“https://www.baidu.com/s?wd=草莓”的信息,从而可以知道百度关键词接口就是该格式。
2、IDLE上进行实操
此处暂时不进行内容解析,只熟悉params参数和关键词接口的使用;360搜索的代码,只需要将wd改为q即可,其余一致。
1 | >>> import requests |
实例4:网络图片的爬取和存储
1、IDLE 实操
打开文件路飞.jpeg,定义为文件标识符f,其中r.content表示返回内容的二进制形式,利用f.write可以写入文件。
1 | >>> import requests |
2、完整代码
异常处理很重要,要考虑周全,功能实现了,不算厉害,要从工程性角度去分析,代码如何执行都不会出错,才是稳定合格的代码。
1 | import requests |
实例5:IP地址归属地的自动查询
1、首先获取接口url
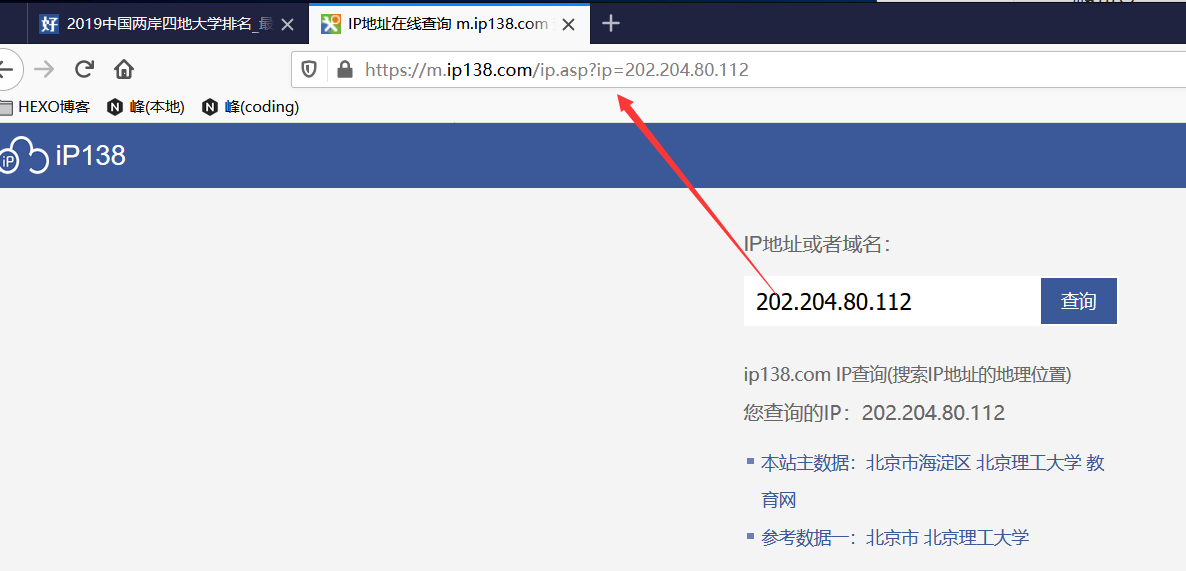
1)类似之前百度搜索那样,直接在网站上输入ip进行查询;
2)如下图,可以看到查询出来的接口url是:
1 | https://m.ip138.com/ip.asp?ip= |
2、IDLE 实操
1 | >>> import requests |
3、完整代码
1 | import requests |
总结
以爬虫视角看待网络内容,静态页面爬取较简单,一切资源都可以看做url,只要将url构建出来,即可进行爬取。
附录
五个实例所有完整代码如下:
1 | import requests |

